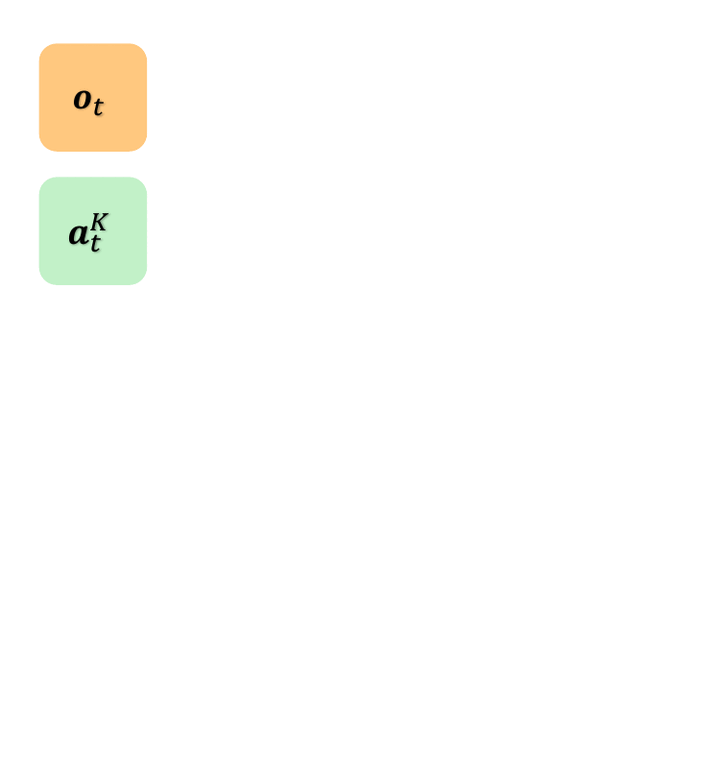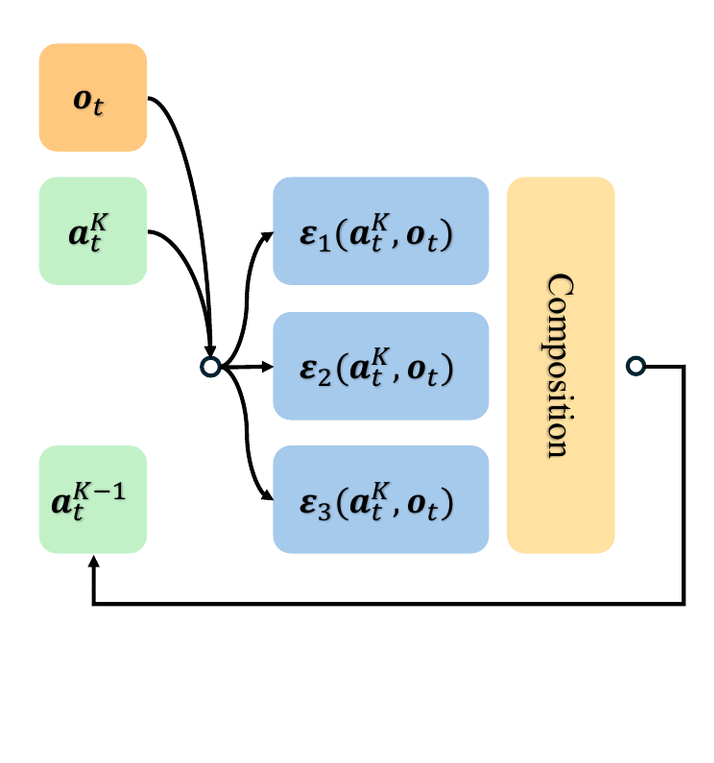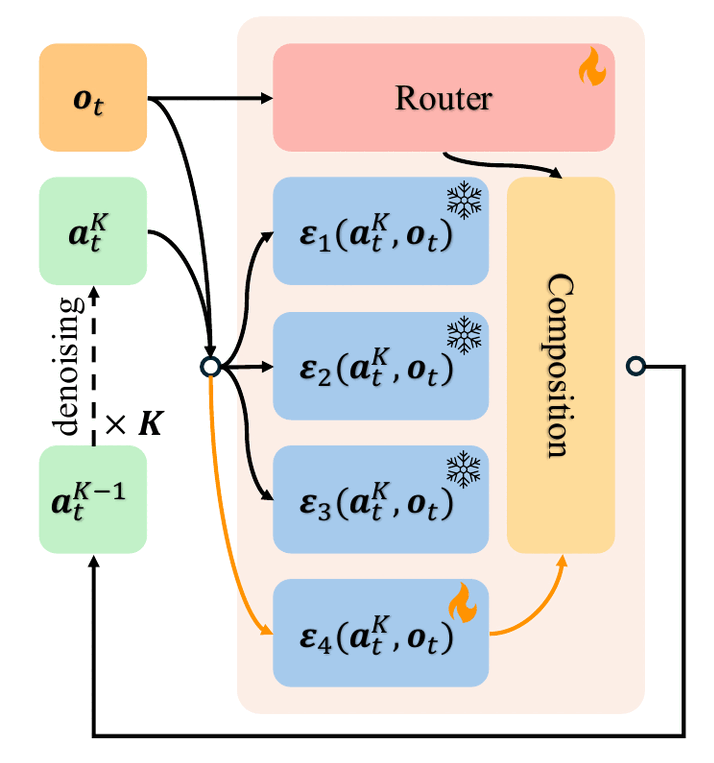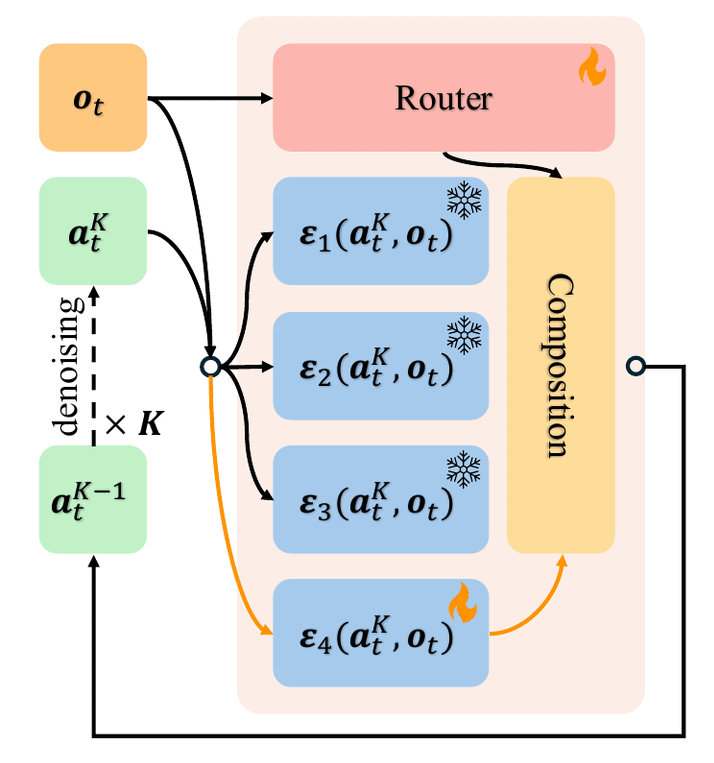
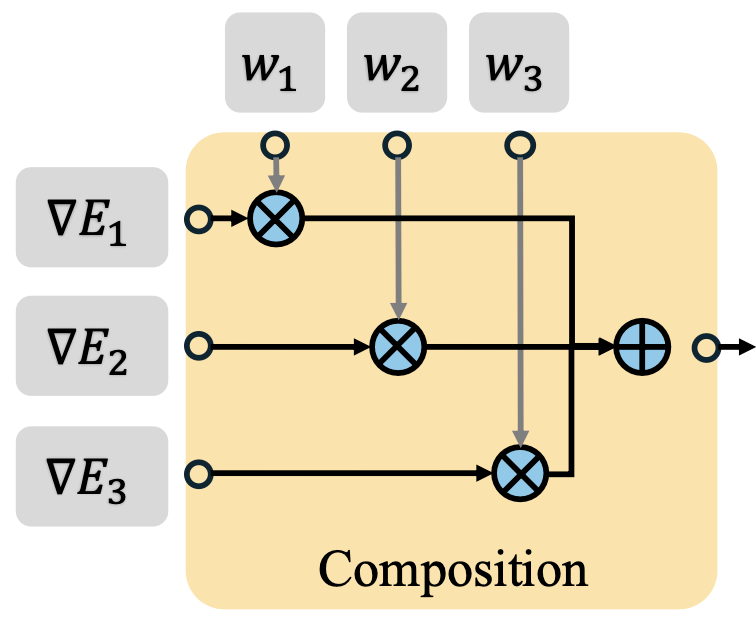
In recent years, large-scale behavioral cloning has emerged as a promising paradigm for training general-purpose robot policies. However, effectively fitting policies to complex task distributions is often challenging, and existing models often underfit the action distribution. In this paper, we present a novel modular diffusion policy framework that factorizes modeling the complex action distributions as a composition of specialized diffusion models, each capturing a distinct sub-mode of the multimodal behavior space. This factorization enables each composed model to specialize and capture a subset of the task distribution, allowing the overall task distribution to be more effectively represented. In addition, this modular structure enables flexible policy adaptation to new tasks by simply fine-tuning a subset of components or adding new ones for novel tasks, while inherently mitigating catastrophic forgetting. Empirically, across both simulation and real-world robotic manipulation settings, we illustrate how our method consistently outperforms strong modular and monolithic baselines, achieving a 24% average relative improvement in multitask learning and a 34% improvement in task adaptation across all settings.
Components 0 and 1 align the robot with the stand, component 2 aligns with the ring, and component 3 executes the grasp.
Components 0 and 1 align and approach the pin, component 2 approaches the hammer, and component 3 performs the grasp.
MetaWorld Multitask |
RLBench Multitask |
Real-world Multitask |
MetaWorld Adaptation |
RLBench Adaptation |
Real-world Adaptation |
X Multitask means the tasks are trained together from scratch.
X Adaptation means the tasks are trained together starting from a model pretrained on X Multitask.